
Hash tables and linked lists are two fundamental data structures commonly used in software development. While each has its distinct advantages, combining them often yields a data structure that leverages the strengths of both.
- Understanding the Advantage and Disadvantage of Them
- Benefits of Combining Hash Tables and Linked Lists
- LRU Cache Elimination Algorithm
- LinkedHashMap in Java
Understanding the Advantage and Disadvantage of Them
Before delving into their combined use, let’s briefly recap what each data structure offers individually:
Hash Tables
- Advantage:
- Provide average-case constant time complexity
O(1)for lookups, insertions, and deletions. They achieve this by using a hash function to map keys directly to indices in an array where values are stored.
- Provide average-case constant time complexity
- Disadvantage:
- The data in the hash table are stored irregularly (order cannot be guaranteed) by the hash function.
Linked Lists
- Advantage:
- Linked Lists are sequential storage model that guarantees the order of data in lists, and the data need not be stored in continuous memory (unlike Arrays).
- Disadvantage:
- Their sequential storage model, however, leads to
O(n)time complexity for random access lookups.
- Their sequential storage model, however, leads to
From the above, it can be seen that:
- When used together, hash tables and linked lists complement each other’s strengths and mitigate their weaknesses.
Benefits of Combining Hash Tables and Linked Lists
Here are the primary advantages of using them in combination:
Maintaining Data Order
Linked lists inherently maintain the order of elements. When combined with hash tables, this property can be used to preserve data insertion order.
- For example, in an LRU cache implemented using a hash table for fast access and a linked list to maintain order, items are:
- Added to the hash table for
O(1)access. - Managed in a linked list to keep track of usage order, making it straightforward to remove the least recently used item when necessary.
- Added to the hash table for
Facilitating Iteration
While hash tables do not inherently support ordered iteration due to their nature of hashing, linked lists do. By linking entries together, you can iterate over items in a hash table efficiently, especially useful in applications requiring traversal of entries, such as maintaining a timestamp-ordered log of transactions.
LRU Cache Elimination Algorithm
A Least Recently Used (LRU) cache is a popular caching algorithm used to manage a set of data in memory that optimises the application’s speed by keeping the most recently accessed items ready for use and discarding the least recently used items when the memory is full.
I have previously discussed how to implement LRU with a linked list. But the time complexity of the LRU implemented using only linked lists is high (O(n)) because looking up the data requires traversing the linked list.
The following section explores how to implement an LRU using hash tables combined with linked lists, a method that offers efficient O(1) complexity for cache operations.
Understanding LRU Cache Mechanism
- Primary operation of LRU cache:
- Accessing Data: When data is accessed, it becomes the most recently used (MRU) data. If the data is not in the cache (a cache miss), it is loaded into the cache from the source (e.g., disk).
- When loading data to the cache, if the cache exceeds its capacity, the least recently used (LRU) data is identified and evicted to make space.
- Accessing Data: When data is accessed, it becomes the most recently used (MRU) data. If the data is not in the cache (a cache miss), it is loaded into the cache from the source (e.g., disk).
- To efficiently implement the operation, the LRU cache algorithm requires:
- Fast access to data to check if it exists in the cache. We can use:
- Hash Table: Provides
O(1)complexity for lookups and deletions. Each key in the hash table will link to a node in a doubly linked list.
- Hash Table: Provides
- A way to quickly see and modify which data was least and most recently used. We can use:
- Doubly Linked List: The list will store the items in the cache with the most recently used items at the front and the least recently used items at the back. This allows
O(1)complexity for seeing and modifying which data was least and most recently used.
- Doubly Linked List: The list will store the items in the cache with the most recently used items at the front and the least recently used items at the back. This allows
- Fast access to data to check if it exists in the cache. We can use:
Implementation of LRU
- Access Data:
- If the data is in the cache (hit), retrieve the data, move the corresponding node to the front of the list to mark it as MRU.
- If the data is not in the cache (miss), load it, store it in the hash table and doubly linked list.
- Insert the new data at the front of the list and in the hash table.
- If the cache is full, remove the LRU item from the hash table and the back of the list before inserting new data.
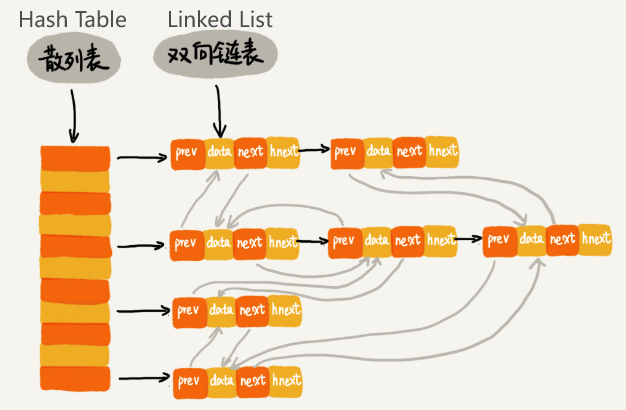 LRU using hash tables combined with (doubly) linked lists
LRU using hash tables combined with (doubly) linked lists
From the above, we can see that each node in the doubly linked list has a special field hnext in addition to data, prev, next.
- What is the purpose of this
hnext?- Because this hash table resolves hash conflicts by the Chaining method. So each node will be in two chains: One chain is a doubly linked list, and the other chain is the conflicting chain in the hash table.
- The
hnextpointer is for chaining nodes in the hash table to resolve conflicts.
LinkedHashMap in Java
Compared to HashMap, LinkedHashMap has one more “Linked”.
- Does the word “Linked” mean that
LinkedHashMapis a hash table that resolves hash conflicts by using linked lists (Chaining)?
- No. “Linked” means that LinkedHashMap combines (doubly) LinkedList with HashMap to provide ordered storage and fast access.
LinkedHashMapextendsHashMapand implements theMapinterface.- It maintains a linked list of the entries in the map, in the order in which they were inserted.
- This linked list defines the iteration ordering, which is normally the order in which keys were inserted into the map (
insertion-ordered). - It also can be configured to
access-ordered, meaning entries are ordered by their last access from least-recently accessed to most-recently. (It’s a bit like LRU)
- Key Characteristics
- Predictable Iteration Order: Unlike
HashMap, which does not guarantee any specific order of iteration,LinkedHashMapprovides a predictable iteration order based on the order of insertion or access. - Performance: Offers slightly lower performance than
HashMapdue to the added expense of maintaining the linked list (additional memory consumption). However, it still provides constant-time performance for basic operations (get,put, andremove), assuming the hash function disperses elements properly among the buckets.
- Predictable Iteration Order: Unlike
Reference:
- Wang, Zheng (2019) The Beauty of Data Structures and Algorithms. Geek Time.
