
Read-write separation is an architectural pattern used to improve the performance, scalability, and reliability of database systems. This pattern is particularly useful for applications with high read and write loads, ensuring that both types of operations are handled efficiently.
- What is Read-Write Separation?
- Example of Implementing Read-Write Separation
- The Challenges of Read-Write Separation
What is Read-Write Separation?
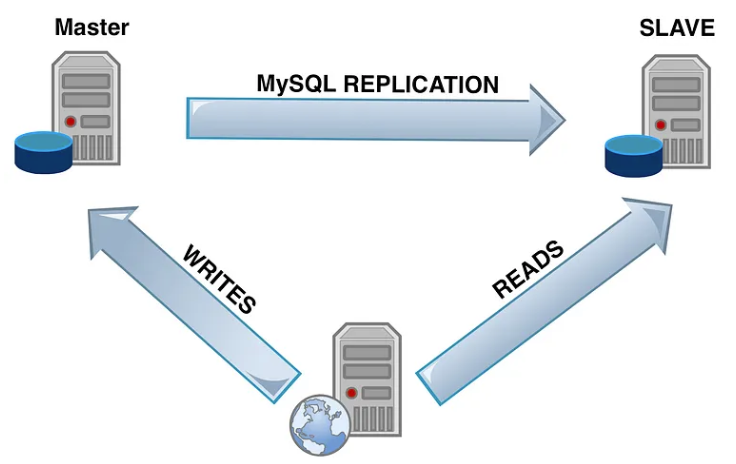
Read-write separation involves splitting the database workload into read operations and write operations, directing them to separate database instances. Typically, a primary database handles all write operations, while one or more secondary (replica) databases handle read operations. This separation helps balance the load and improve overall system performance.
Key Components
- Primary (Master) Database: The main database instance responsible for processing all write (insert, update, delete) operations. It ensures data consistency and integrity.
- Secondary (Slave) Databases: One or more read-only replicas of the primary database that handle read (select) operations. These replicas are synchronized with the primary database.
- Replication Mechanism: The process that keeps the secondary databases updated with changes from the primary database. This can be synchronous or asynchronous.
Benefits of Read-Write Separation
- Improved Performance
- By directing read operations to secondary databases, the primary database is relieved of read load, allowing it to handle write operations more efficiently. This leads to better performance for both reads and writes.
- Scalability
- Read-write separation allows the system to scale horizontally. As read load increases, more read replicas can be added to distribute the load. This approach ensures that the system can handle growing traffic without a degrading performance.
- Fault Tolerance
- With multiple read replicas, the system can continue to serve read requests even if the primary database goes down. This improves the system’s fault tolerance and availability.
- Optimized Resource Utilization
- By separating reads and writes, resources can be allocated and optimized for each type of operation. For example, read replicas can be optimized for query performance, while the primary database can be optimized for transaction processing.
Example of Implementing Read-Write Separation
Step 1: Set Up the Primary Database
The primary database is responsible for handling all write operations. Choose a database system that supports replication, such as MySQL, PostgreSQL, or MongoDB.
Step 2: Configure Read Replicas
Set up one or more read replicas of the primary database. These replicas will handle read operations and should be configured to replicate data from the primary database. Depending on the database system, this may involve configuring replication settings and ensuring that the replicas are updated in real-time or near real-time.
Step 3: Implement a Proxy
To direct read and write operations to the appropriate database instances, implement a proxy layer. This layer intercepts database requests from the application and routes them to the correct database based on the type of operation.
Here’s a simple example of how read-write separation can be implemented in a Java application using Spring Boot and a MySQL database:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
@Configuration
public class DataSourceConfig {
@Bean
@Primary
@ConfigurationProperties("spring.datasource")
public DataSource primaryDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.read-datasource")
public DataSource readDataSource() {
return DataSourceBuilder.create().build();
}
@Bean
public DataSourceRouting dataSourceRouting() {
DataSourceRouting dataSourceRouting = new DataSourceRouting();
Map<Object, Object> targetDataSources = new HashMap<>();
targetDataSources.put(DataSourceType.WRITE, primaryDataSource());
targetDataSources.put(DataSourceType.READ, readDataSource());
dataSourceRouting.setTargetDataSources(targetDataSources);
dataSourceRouting.setDefaultTargetDataSource(primaryDataSource());
return dataSourceRouting;
}
@Bean
public JdbcTemplate jdbcTemplate(DataSourceRouting dataSourceRouting) {
return new JdbcTemplate(dataSourceRouting);
}
}
In this example:
- DataSourceConfig: Configures the primary and read data sources.
- DataSourceRouting: A custom routing data source that routes read and write operations to the appropriate data sources based on the operation type.
- JdbcTemplate: A Spring component used to interact with the database.
Step 4: Modify the Application Logic
Ensure that the application logic directs read and write operations to the appropriate data source. This can be done by annotating methods or using a custom aspect to intercept and route database operations.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@Service
public class UserService {
private final JdbcTemplate jdbcTemplate;
public UserService(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Transactional
@ReadOnlyConnection // Custom Annotation
public List<User> getUsers() {
return jdbcTemplate.query("SELECT * FROM users", new UserRowMapper());
}
@Transactional
public void addUser(User user) {
jdbcTemplate.update("INSERT INTO users (name, email) VALUES (?, ?)", user.getName(), user.getEmail());
}
}
In this example:
- getUsers: A read operation annotated with
@ReadOnlyConnectionto indicate that it should use the read data source. - addUser: A write operation that uses the primary data source.
The Challenges of Read-Write Separation
Replication Latency
Replication latency refers to the time delay between when a write operation occurs on the master database and when it is reflected on the slave databases. This latency can affect the consistency and accuracy of read operations if the slave databases are not immediately up-to-date.
For example, a user just registers and immediately logs in. If there is a long replication latency, the server will indicate that the user has not yet registered.
Causes of Replication Latency
- Network Delays: Latency due to the time it takes for data to travel between the master and slave databases.
- Load on Master: High write loads on the master can slow down the replication process.
- Slave Performance: The performance of the slave databases in processing and applying the replication logs can introduce delays.
- Replication Method: Synchronous replication minimizes latency but can slow down write operations. Asynchronous replication is faster but introduces higher latency.
How to Resolve Problems Caused by Replication Latency
- Read operations after write operations are designated to be sent to the master database.
- Pros: This ensures that you read the up-to-date data (if the database is available).
- Cons: This approach is strongly tied to the business and is more intrusive and impactful. For example, if a new programmer is unfamiliar with the business, this can lead to a bug.
- Re-read from the Master Database if Read from the Slave Fails. (We can use the timestamp to determine if the data from the Slave is up-to-date, if not then the read fails.)
- Pros: Non-intrusive to business logic, only requires encapsulation at the underlying database access API.
- Cons: If there are many failed reads, it might increase the load on the master database (hackers may leverage this vulnerability).
- Critical business read/write operations directed to the Master, non-critical business using read/write separation.
- Pros: Ensures data consistency for critical operations. And reduces the load pressure on the master database.
- Cons: May need additional mechanisms to identify and distinguish between critical and non-critical operations. And requires categorization and design of business logic, increasing development and maintenance complexity.
In summary, all methods have their own advantages and disadvantages. It is necessary to choose the appropriate method according to the specific business requirements.
Distribution Mechanisms
Effective distribution of read and write operations is crucial in a read-write separated architecture to ensure optimal performance and consistency.
This can generally be done in two ways: code encapsulation and middleware encapsulation.
Code Encapsulation
Code encapsulation involves abstracting a data access layer in the code, which manages the separation of read and write operations and the connection to database servers. For example, the above implementation example is based on this approach.
- Pros:
- Simple to implement and allows for extensive customization based on business needs.
- Cons:
- Each programming language needs to implement it separately, making it non-generalizable. If a business includes multiple systems written in different programming languages, the repetitive development workload is substantial.
- In case of failure and master-slave switch, all systems may need to modify configurations and restart.
Middleware Encapsulation
Middleware encapsulation refers to establishing a separate system to manage read-write separation and database server connections. The middleware provides SQL-compatible protocols to business servers, so the business servers do not need to handle read-write separation themselves. For business servers, accessing the middleware is the same as accessing the database; essentially, the middleware appears as a database server to them.
- Pros:
- Supports multiple programming languages because the middleware provides standard SQL interfaces to business servers.
- Business servers do not need to be sensitive to master-slave switch.
- Cons:
- The middleware needs to support the complete SQL syntax and database server protocols (e.g., MySQL client and server connection protocols), making the implementation complex and detailed, prone to bugs, and requiring a long time to stabilise.
- The middleware itself does not perform actual read-write operations, but all database operation requests must go through the middleware, so its performance requirements are high.
Due to the complexity of middleware encapsulation compared to code encapsulation, it is generally recommended to use code encapsulation or mature open-source database middleware (e.g., MySQL Router).
For large companies, investing in developing their own database middleware can be worthwhile, as once the system is built, the more business systems that integrate with it, the more development cost savings can be achieved, thus increasing its value.
Reference:
-
Li, Yunhua (2018) Learn Architecture from 0. Geek Time.
-
https://medium.com/@mena.meseha/mysql-read-and-write-separation-4167d99b337c
