
- What is Reverse Engineering?
- Different Representations of Reverse Engineering
- Overall Process of Reverse Engineering
- System-Level Reversing & Code-Level Reversing
- Reverse Engineering Tools
- Security-Related Reversing & Software Development-Related Reversing
- Legal Implication Around Reversing
What is Reverse Engineering?
- A process where an engineered artifact (such as a car, a jet engine, or a software program) is deconstructed
- In a way that reveals its inner-most details, such as its design and architecture
- In the software world,
- Taking an existing program for which source-code or proper documentation is not available
- Attempting to recover details regarding its design and implementation
- Software is one of the most complex and intriguing technologies around us nowadays, and software reverse engineering is about opening up a program’s “box” and looking inside.
- Reverse engineering requires a combination of skills and a thorough understanding of computers and software development
- Reverse engineering integrates several arts: code breaking, puzzle solving, programming, and logical analysis
Different Representations of Reverse Engineering
- Zero level: Machine code (ones and zeros)
- Machine code (often called binary code, or object code) is sequences of bits that contain a list of instructions for the CPU to perform
- CPUs can only run machine code
- The instructions depend on the architecture of CPUs
- How a CPU consumes the data
- Each instruction performs a very specific task, such as moving data between registers or performing arithmetic operations.
- It is difficult for humans to read or write
- requires knowledge of specific numerical codes for every instruction on a given machine
- Low level: Assembly instructions
- Assembly language is simply a textual representation of bits in machine code
- We name elements in these code sequences in order to make them human-readable
- Instead of cryptic hexadecimal numbers, we can look at textual instruction names such as
MOV(Move),XCHG(Exchange), and so on- we call these as “mnemonics”
- Each assembly language command is represented by a number, called the operation code, or opcode
- Every computer architecture has its own assembly language that is usually quite different from all the rest
- Therefore, assembly language is a class of languages, not one language
- Despite being more readable than machine code, it still requires a deep understanding of the computer’s architecture
- It is used for direct hardware manipulation or extreme optimization.
- Assembly language is simply a textual representation of bits in machine code
- Machine code and assembly language are two different representations of the same thing.
- Machine code is not “faster” or “lower-level” than assembly language
- Both machine code and assembly language instructions execute at the same speed on the hardware, because assembly code is essentially a human-readable representation of machine code.
- Although assembly language is “Low level” and machine code is “Zero level”, this distinction is somewhat semantic, as assembly language is directly mapped to machine code.
- Intermediate level: Programming languages (C, C++)
- There isn’t a formal category named “intermediate level programming languages” in the traditional sense. In general, they belong to high-level languages.
- However, some languages or technologies might be considered intermediate in the sense that they offer a balance between high-level abstraction and low-level control.
- they provide some level of abstraction but also allow detailed control over system resources.
- High level: Programming languages (Python, Java)
- These languages are much closer to human languages and are more abstracted from the details of the computer’s hardware.
- They are designed to be easy to read, write, and maintain.
- They are used for a wide range of applications, from web development to software engineering.
Overall Process of Reverse Engineering
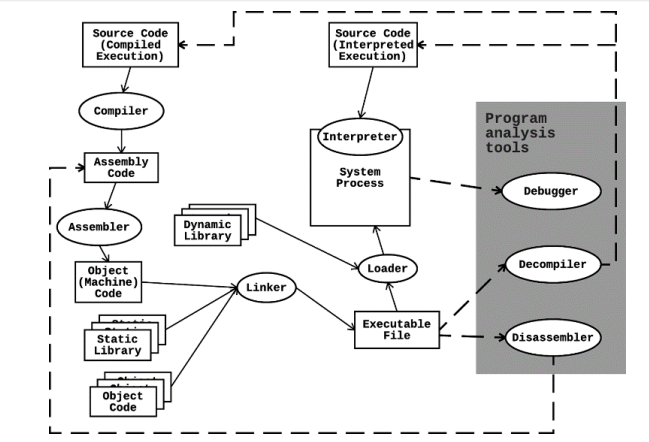
Compiled Execution & Interpreted Execution
In the picture above, we can see two different source codes:
- Compiled Execution Source Code
- Compilation is the process where source code written in a high-level (or intermediate-level) programming language (like C, C++, or Rust) is translated into machine code by a compiler. This machine code is specific to the target computer’s architecture and can be executed directly by the computer’s CPU.
- The compilation process happens before the program is run. This means there can be a significant delay between writing code and executing it, but once compiled, the code usually runs faster because it’s already in the machine’s native language.
- Compiled code is platform-specific. A program compiled for one type of hardware or operating system typically cannot run on another without recompilation.
- Interpreted Execution Source Code
- Interpretation involves executing source code directly, line by line, by an interpreter. The interpreter reads the high-level program code and performs the instructions instantly, without converting it into machine code ahead of time. Interpreter translates instructions to machine code in real-time as the program runs.
- Since interpretation happens in real-time, it’s possible to write and test code more rapidly than with compiled languages, making it suitable for rapid development and scripting.
- Interpreted code tends to run slower than compiled code because of the overhead of interpreting instructions instantly. However, modern interpreters and just-in-time (JIT) compilation techniques have significantly narrowed this performance gap for many tasks.
- Interpreted code is more portable across different platforms, as the same source code can run anywhere the interpreter is available, regardless of the underlying hardware.
Related Concepts
Object Code
- Object code is essentially a sequence of opcodes and other numbers used in connection with the opcodes to perform operations
- CPUs constantly read object code from memory, decode it, and act based on the instructions embedded in it
- An assembler translates the textual assembly language code into binary code
- A disassembler does the exact opposite
Compliers
- A compiler takes a source file and generates a corresponding machine code file
- The source file would contain instructions that describe the program in a high-level language such as Java
- This machine code file can either be
- A standard platform-specific object code that is decoded directly by the CPU
- Or it can be encoded in a special platform-independent format called bytecode
- Compilers of traditional (non-bytecode-based) programming language such as C and C++ directly generate machine-readable object code from the textual source code
Java Virtual Machines (JVMs)
- Compilers for Java generate a bytecode instead of an object code
- Bytecodes are similar to object codes
- Except that they are usually decoded by a program (such as JVM), instead of a CPU
- Java Virtual Machine decodes (Interprets) the bytecode and performs the operations described in it.
- So Java is both Compiled Execution and Interpreted Execution.
- The virtual machine can be ported to different platforms, which enables running the same program on any CPU as long as it has a compatible virtual machine
- Platform independence (cross-platform)
Operating Systems
- An operating system is a program that manages a computer, including hardware devices and software applications
- An operating system takes care of many different tasks and can be seen as a kind of coordinator between the different elements in a computer
- An operating system serves as a gatekeeper that controls the link between applications and the outside world
- Many reversing techniques revolve around the operating system
- Any reverser must have a good understanding of what Operating Systems do and how Operating Systems work
System-Level Reversing & Code-Level Reversing
- Reversing sessions can be divided into two separate phases:
- System-level reversing: large-scale observation of the earlier program
- Code-level reversing: more in-depth work
System-level Reversing
- System-level reversing techniques help determine the general structure of the program and sometimes even locate areas of interest within it.
- System-level reversing involves running various tools on the program and utilising various operating system services to obtain information, inspect program executables, track program input and output.
- Most of this information comes from the operating system, because by definition, every interaction that a program has with the outside world must go through the operating system
- Reversers must understand operating systems
Code-level Reversing
- Code-level reversing techniques provide detailed information on a selected code chunk
- Extracting design concepts and algorithms from a program binary
- It is a complex process that requires a mastery of reversing techniques along with a solid understanding of software development, the CPU, and the operating system
- Code-level reversing observes the code from a very low-level, with every little detail of how the software operates
- Many of these details are generated automatically by the compiler and not manually by the software developer
- Reversers need a solid understanding of the low-level aspetcs of software
Reverse Engineering Tools
System-monitoring Tools
- System-level reversing requires a variety of tools that sniff, monitor, explore, and expose the program being reversed
- Because almost all communications between a program and the outside world go through the operating system, the operating system can usually be leveraged to extract such information
- System-monitoring tools can monitor networking activity, file accesses, registry access and so on
- There are also tools that expose a program’s use of operating system objects such as mutexes, events, and so forth
Disassemblers
- Disassemblers are programs that take a program’s executable binary as input and generate textual files that contain the assembly language code for the entire program or parts of it
- This is a relatively simple process considering that assembly language code is simply the textual mapping of the object code
- Disassembly is a processor-specific process, but some disassemblers support multiple CPU architectures
 IDA Pro – Disassembler
IDA Pro – Disassembler
Debuggers
- A debugger is a program that allows software developers to observe their program while it is running
- The two most basic features in a debugger are the ability to set breakpoints and the ability to trace through code
- Breakpoints allow users to select a certain function or code line anywhere in the program and instruct the debugger to pause program execution once that line is reached
- Tracing means the program executes one line of code and then freezes, allowing the user to observe or even alter the program’s state
- This allows developers to view the exact flow of a program at a pace more appropriate for human comprehension
- Reversers use debuggers (such as OllyDbg) in disassembly mode
- In disassembly mode, a debugger uses a built-in disassembler to disassemble object code on the fly
- Reversers can step through the disassembled code and essentially watch the CPU as it’s running the program on instruction at a time
- Reversers can install breakpoints in locations of interest in the disassembled code and then examine the state of the program
Decompilers
- Decompilers (such as 9Rays Spices .Net) are the next step up from disassemblers
- Takes an executable binary file and attempts to produce readable high-level language code from it
- The idea is to try and reverse the compilation process, to obtain the original source code or something similar to it
- On the vast majority of platforms, actual recovery of the original source code isn’t really possible
- Significant elements are just omitted during the compilation process (for optimisation) and are impossible to recover
Security-Related Reversing & Software Development-Related Reversing
Security-related reversing
- Malicious Software
- Malware (Malicious Software) developers often use reversing to locate vulnerabilities in operating systems and other software
- Such vulnerabilities can be used to penetrate the system’s defense layers and allow infection
- Malware analysts dissect and analyse every malware that falls into their hands
- They use reversing techniques to trace every step the malware takes and assess the damage it could cause, how it could be removed from infected systems, and whether infection can be avoided altogether
- Malware (Malicious Software) developers often use reversing to locate vulnerabilities in operating systems and other software
- Reversing Cryptographic Algorithms
- In restricted cryptographic algorithms, the secret is the algorithm itself
- Once the algorithm is exposed, it is no longer secure
- Reversing makes it very difficult to maintain the secrecy of the algorithm
- Once reversers get their hands on the encrypting or decrypting program, it is only a matter of time before the algorithm is exposed.
- Because the algorithm is the secret, reversing can be seen as a way to break the cryptographic algorithm.
- In response to reversing, key-based algorithms are used, where the secret is a key.
- Users encrypt and decrypt messages using keys
- The algorithms are usually made public, and the keys are kept private
- This almost makes reversing pointless because the algorithm is already known
- In restricted cryptographic algorithms, the secret is the algorithm itself
- Digital Rights Management
- Digital information is incredibly fluid
- It is very easy to move around and can be very easily duplicated
- This fluidity means that once the copyrighted materials reach the hands of consumers, they can be moved and duplicated so easily that piracy almost becomes common practice
- Traditionally, software companies have dealt with piracy by embedding copy protection technologies into their software
- These are additional pieces of software embedded on top of the vendor’s software product that attempt to prevent or restrict users from copying the product
- These technologies are called digital rights management (DRM)
- By using reversing techniques, a cracker can learn the inner secrets of the technology and discover the simplest possible modification that could be made to the program in order to disable the protection
- Digital information is incredibly fluid
- Auditing Program Binaries
- One of the strengths of open-source software is that it is often inherently more dependable and secure
- Impartial software engineers inspect and approve open-source software
- Certain vulnerabilities and security holes can be discovered very early on
- With proprietary software for which source code is unavailable, reversing becomes a viable (yet admittedly limited) alternative for searching for security vulnerabilities
- Reverse engineering cannot make proprietary software nearly as accessible and readable as open-source software
- But strong reversing skills enable one to view code and assess the various security risks it poses
- One of the strengths of open-source software is that it is often inherently more dependable and secure
Software development-related reversing
- Interoperability
- Interoperability is where most software engineers can benefit from reversing almost daily
- When working with a proprietary software library or operating system API, documentation is almost always insufficient
- Regardless of how much trouble the library vendor has taken to ensure that all possible cases are covered in the documentation
- Users almost always find themselves scratching their heads with unanswered questions
- Using reversing, it is possible to resolve many of these problems in very little time and with a relatively small effort
- Developing Competing Software
- It would never make sense to reverse engineer the competitor’s entire product
- It is usually much easier to design and develop a product from scratch, or simply licence the more complex components from a third party
- When it comes to highly complex or unusual components, they might be reversed and reimplemented in the new product
- But some legal implication
- Evaluation of Software Quality and Robustness
- Software vendors that don’t publish their software’s source code are essentially asking their customers to “just trust them”
- Buying a used car where you can’t pop up the hood
- Reversing would never reveal as much about the product’s code quality and overall reliability as taking a look at the source code, but it can be highly informative
- Software vendors that don’t publish their software’s source code are essentially asking their customers to “just trust them”
Legal Implication Around Reversing
Is Reversing Legal?
- The legal debate around reverse engineering has been going on for years
- It usually revolves around the question of what social and economic impact reverse engineering has on society as a whole
- It is never going to be possible to accurately predict whether a particular reversing scenario is legal or not
- Always seek legal counsel before getting yourself into any high-risk reversing project
Digital Millennium Copyright Act (DMCA)
- DMCA was enacted in 1998 to protect the copyright protection technologies
- The idea is that the copyright protection technologies in themselves are vulnerable and that legislative action must be taken to protect them
- It legally protects copyright protection systems from circumvention
- “Circumvention of copyright protection systems” almost always involves reversing
- DMCA only applies to copyright protect systems but does not apply to any other type of copyrighted software
