
In the realm of distributed systems, the CAP theorem is a cornerstone principle that every software architect should understand. Formulated by computer scientist Eric Brewer in 2000, the CAP theorem provides a framework for understanding the trade-offs involved in designing distributed systems.
The CAP Theorem, while important, has never been rigorously defined. In this blog, I will discuss the understanding of CAP Theorem by referring to different sources.
- What is the CAP Theorem?
- Rigorous CAP Theorem
- Implications of the CAP Theorem
- Key Detail Points of the CAP Theorem
- Other Relevant Concepts
What is the CAP Theorem?
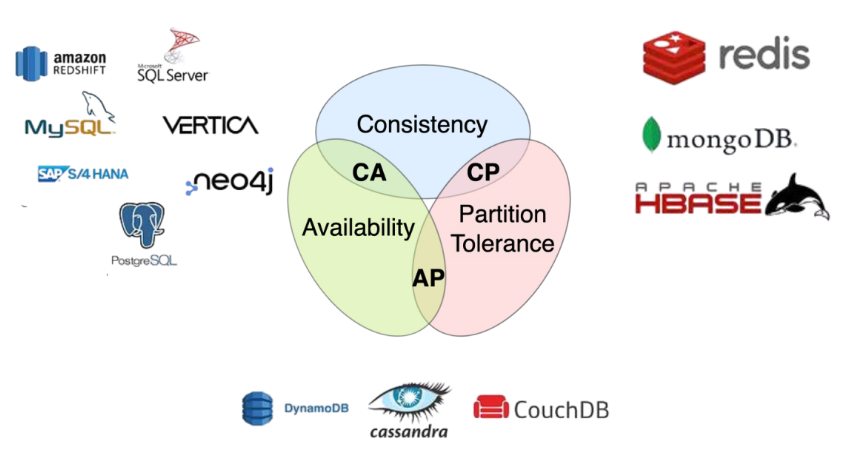
The CAP theorem, also known as Brewer’s theorem, posits that in any distributed data store, it is impossible to simultaneously achieve all three CAP properties.
CAP refers to Consistency, Availability, Partition Tolerance. When Brewer proposed CAP, he did not define Consistency, Availability and Partition Tolerance in detail, so there are some slight differences in the detailed definitions of CAP in different sources. Here, I’ll show definitions from two of the sources:
- The definitions from Wikipedia
- Consistency (C): Every read receives the most recent write or an error.
- Availability (A): Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
- Partition Tolerance (P): The system continues to operate despite an arbitrary number of messages being dropped ( or delayed) by the network between nodes.
- The definitions from IBM Cloud
- Consistency (C): where all nodes see the same data at the same time.
- Availability (A): which guarantees that every request receives a response about whether it succeeded or failed.
- Partition Tolerance (P): where the system continues to operate even if any one part of the system is lost or fails.
According to the CAP theorem, a distributed system can satisfy at most two of these three properties at any given time, but not all three. This forces architects to make trade-offs based on the specific requirements and constraints of their applications.
Rigorous CAP Theorem
In order to better explain the CAP theorem, I picked the article by Robert Greiner as the reference base. Interestingly, Robert Greiner’s understanding of CAP went through a process. He wrote two articles on CAP theorem, and the first article was labelled outdated. He wrote in the second article:
Close to two months ago, I wrote a blog post explaining the CAP Theorem. Since publishing, I’ve come to realize that my thinking on the subject was quite outdated and is no longer applicable to the real world. I’ve attempted to make up for that in this post.
In the second edition, this is how he explains the CAP theorem:
The CAP Theorem states that, in a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance - one of them must be sacrificed. However, as you will see below, you don’t have as many options here as you might think.
There are two things to notice here:
- interconnected & share data: Why do the authors emphasise these two points? Because distributed systems do not necessarily interconnect and share data. Clusters of Memcache, for example, are not connected to each other and do not share data, so distributed systems such as Memcache clusters do not fit into the objects explored by CAP theorem.
- write/read: CAP focuses on read and write operations on data rather than all the functions of a distributed system. For example, ZooKeeper’s leader election is not something that CAP focuses on.
Consistency (C)
The first edition:
All nodes see the same data at the same time.
The second edition:
A read is guaranteed to return the most recent write for a given client.
- The first edition is described from the viewpoint of the node, while the second edition is described from the viewpoint of the client.
- The keyword in the first edition is see, and in the second edition it is read.
- The first edition emphasised “same data at the same time”, the second edition did not emphasise this.
- This means that in practice it is possible for nodes to have different data at the same moment. This is different from what we usually understand by consistency, why? This is because, during the execution of the transaction, the data of different nodes is not completely same. The client cannot read uncommitted data while the transaction is executing.
Availability (A)
The first edition:
Every request gets a response on success/failure.
The second edition:
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
- “every request” to “A non-failing node”: The first edition of “every request” is not rigorous, as only non-failing nodes can satisfy the availability requirement.
- “response on success/failure” to “reasonable response within a reasonable amount of time (no error or timeout)”: The first edition’s definition of “success/failure” was too general. In almost any case, we can say that the request succeeded or failed (since timeouts and errors are considered failures).
Partition Tolerance (P)
The first edition:
System continues to work despite message loss or partial failure.
The second edition:
The system will continue to function when network partitions occur.
Network Partition: a division of a computer network into relatively independent subnets (i.e., they can’t communicate with each other).
A Network Partition refers to a network scenario in distributed systems where some nodes become unreachable due to network failures or disruptions.
- “work” to “function”: As long as the system is not down, we can say that the system is working. Function emphasises “performing the responsibility”, which is compatible with availability.
- “message loss or partial failure” to “network partitions”: The definition of “message loss” is a bit narrow, since it is only one type of network partitions.
Implications of the CAP Theorem
Although CAP theorem defines that only two of the three elements can be taken, thinking about it in a distributed environment, we find that the P (Partition Tolerance) element must be chosen because the network itself cannot be 100% reliable. Therefore, it is theoretically impossible to choose a CA architecture for a distributed system, but only a CP or AP architecture.
CP
- CP (Consistency and Partition Tolerance): Systems that prioritize consistency and partition tolerance will sacrifice availability. These systems ensure data consistency across nodes, but may become unavailable during network partitions.
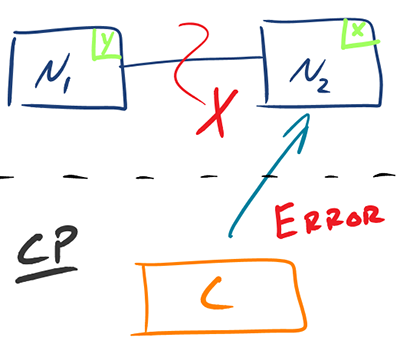 CP: No Availability (may return ERROR)
CP: No Availability (may return ERROR)
Example: Traditional relational databases like MySQL configured for strong consistency.
AP
- AP (Availability and Partition Tolerance): Systems that prioritize availability and partition tolerance will sacrifice consistency. These systems remain available even during network partitions but may return stale or inconsistent data.
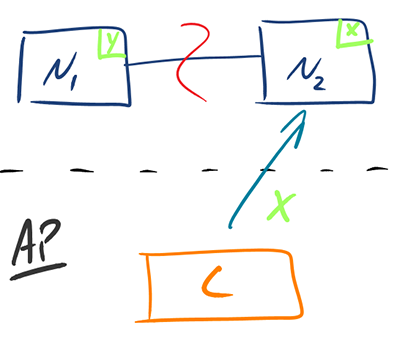 AP: No Consistency (may return value which is not the most recent)
AP: No Consistency (may return value which is not the most recent)
Example: NoSQL databases like Cassandra, which are designed for high availability and partition tolerance.
CA (non-distributed system)
- CA (Consistency and Availability): Systems that prioritize consistency and availability will sacrifice partition tolerance. These systems are theoretically impossible to implement in distributed environments because they cannot handle network partitions effectively.
Example: Some highly available single-node databases, which do not need to handle network partitions.
Key Detail Points of the CAP Theorem
CAP focuses on the granularity of the data, not the entire system.
The trade-off between C and A can occur repeatedly within the same system at a very fine granularity. And each decision may be different depending on the specific operation, or even on the particular data or users involved.
In the definition and explanation of CAP theorem, such system-level concepts as system and node are used, which gives many people a big misleading impression that the whole system can either choose CP or AP when we design the architecture. However, in the actual design process, each system cannot handle only one type of data, but contains multiple types of data, some of which must be selected for CP and some for AP.
CAP ignores network latency.
This is a very implicit assumption. Brewer does not take latency into account when defining consistency.
The CAP theorem is based on an ideal condition: when the transaction commits, the data can be copied to all nodes instantly. In reality, however, it always takes time to replicate data from node A to node B. This means that the C in CAP theorem cannot be perfectly achieved in practice, and in the process of data replication, the data of node A and node B are not consistent.
For some harsh business scenarios (e.g. user balance related to money), it is technically impossible to achieve perfect consistency in a distributed scenario. However, this type of business must require consistency, so only the CA can be selected. That is, you can only write to a single point, and the other nodes do backups, and you can’t do multi-point writes in a distributed situation.
Please note that this does not mean that this type of system cannot apply a distributed architecture. As mentioned earlier, CAP focuses on the granularity of the data. Only part of the data can’t be made distributed, but the system as a whole can still apply a distributed architecture.
CA can be implemented in distributed systems when network partition does not occur.
A good architectural design considers both scenarios:
- Choose CP or AP when network partition occurs
- Ensure CA when network partition does not occur
The precondition of CAP theorem is that there is a ‘network partition’ of the system. If no network partition occurs in the system (all network connections between nodes are working fine), we do not need to give up C or A. Both C and A should be guaranteed.
Giving up C or A doesn’t mean doing nothing.
Giving up C or A doesn’t mean doing nothing, and the system needs to be prepared for when the network partition is restored.
Most typically, some logs are recorded during network partition. And when the partition failure is resolved, the system performs data recovery based on the logs, allowing the CA state to be reached again.
Other Relevant Concepts
ACID
ACID theory is proposed to ensure the correctness of the transaction in the DBMS (database management system).
ACID contains four constraints:
- Atomicity: A transaction in all operations, either all complete, or none complete (they do not end somewhere in the middle).
- Consistency: Before the start of the transaction and after the end of the transaction, the integrity of the database has not been destroyed (For example, no matter how two users transfer money between them, the sum of their balances should not change).
- Isolation: Concurrent transactions do not interfere with each other. Isolation can prevent the inconsistency caused by the concurrent execution of transactions.
- Durability: After the transaction is over, the modification of the data is permanent (data will not be lost even if the system fails).
CAP describes the distributed system, and ACID describes the database management system. They’re not comparable.
- A (Atomicity) in ACID and A (Availability) in CAP have completely different meanings.
- Although the C (Consistency) in ACID and the C (Consistency) in CAP have the same name, they have completely different meanings.
BASE
ACID and BASE represent two opposing design concepts:
- ACID is a design concept for traditional databases, pursuing a strong consistency model.
- BASE is a design concept for distributed systems, which proposes to sacrifice strong consistency to gain availability (due to network partition).
BASE, like CAP, is used to describe distributed systems. The core idea of BASE is that even if it is not possible to achieve strong consistency (Consistency of CAP is strong consistency), it is possible to achieve eventual consistency in a suitable way.
BASE refers to:
- Basically Available (BA): Distributed systems are allowed to lose partial availability in the event of a failure, i.e., core availability is guaranteed.
- Soft State (S): An intermediate state of the system is allowed to exist. And this intermediate state will not affect the overall availability of the system. The intermediate state refers to the data inconsistency in CAP theory.
- Eventual Consistency (E): All data in a system can eventually reach a consistent state after a certain amount of time.
The BASE theory is essentially an extension and complement to CAP. More accurately, it is a complement to the AP in CAP.
As mentioned before: the C in CAP theorem cannot be perfectly achieved in practice. So, we need BASE.
CAP is the theorem of distributed system design. BASE is an extension and complement of the AP in CAP.
Reference:
- Li, Yunhua (2018) Learn Architecture from 0. Geek Time.
- https://en.wikipedia.org/wiki/CAP_theorem
- https://cloud.ibm.com/docs/Cloudant?topic=Cloudant-cap-theorem
- https://robertgreiner.com/cap-theorem-revisited/
- https://www.linkedin.com/pulse/cap-theorem-optimizing-database-selection-enhanced-application-kar–ey86f/
