
Hash tables are one of the most fundamental data structures in computer science, pivotal for enabling rapid data retrieval. Their efficiency and performance in accessing data make them indispensable in a wide range of applications, from language interpreters to database indexing.
What is a Hash Table?
A hash table, also known as a hash map, is a data structure that implements an associative array, a structure that can map keys to values. A hash table uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
How Hash Tables Work

The primary mechanism of a hash table involves:
- Hashing: Utilizing a hash function to convert the input key into an index.
- Key-Value Pair Storage: Storing values in an array structure based on the hashed key index.
- Collision Handling: Managing two keys that hash to the same index using methods like chaining (linked lists at each bucket) or open addressing (finding another slot using probing techniques).
Advantages of Hash Tables
- Efficient Data Retrieval: Offers average-case constant time complexity, O(1), for lookups, inserts, and deletions.
- Dynamic Resizing: Most implementations can grow as needed to store more elements.
- Flexible Keys: Can handle nearly any type of data as a key.
Challenges with Hash Tables
- Collision Handling: Requires extra logic and can degrade to O(n) time complexity in the worst case.
- Memory Usage: Over-allocation of memory to minimize collisions can lead to inefficient use of space.
- Hash Function Sensitivity: The performance heavily relies on the quality of the hash function used.
Practical Uses of Hash Tables
- Database Indexing: Hash tables provide quick access to data records, speeding up query processing.
- Caching: Implementations like Memcached use hash tables to store web page fragments or results of database calls.
- Programming Languages: Structures like dictionaries in Python, objects in JavaScript, and maps in Java are implemented using hash tables.
Handling Hash Collisions
A hash collision occurs when two or more keys computed by the hash function map to the same index in the hash table. The probability of collisions increases with the number of entries and depends significantly on the quality of the hash function and the size of the hash table. Effective collision handling is essential to ensure quick access times and system efficiency.
Open Addressing
Open addressing resolves collisions by probing for the next available slot within the hash table array itself. If a collision occurs, the hash table checks the next slot (as determined by the probing technique) and continues this process until an empty slot is found.
Common Probing Techniques
- Linear Probing: Checks the next slot in a linear sequence.
- Quadratic Probing: Checks slots by adding a quadratic polynomial to the index.
- Double Hashing: Uses a second hash function to determine the interval between probes.
Example (Linear Probing)
 insert
insert x to hash table (Linear Probing)
 search for
search for y when y is in hash table(Linear Probing)
 search for
search for y when y is not in hash table(Linear Probing)
For hash tables that use Linear Probing to resolve conflicts, the delete operation is slightly more complicated. We cannot simply set a deleted element to null.
As you can see from the above figure, during the search, once we have found a free position through the Linear Probing, we can determine that this data does not exist in the hash table. However, if this free position is one that we later delete, it will cause the original search algorithm to fail.
To solve this problem we can specially mark deleted elements as deleted, and when a linear search encounters a space marked as deleted, it doesn’t stop, but continues to search down the list.
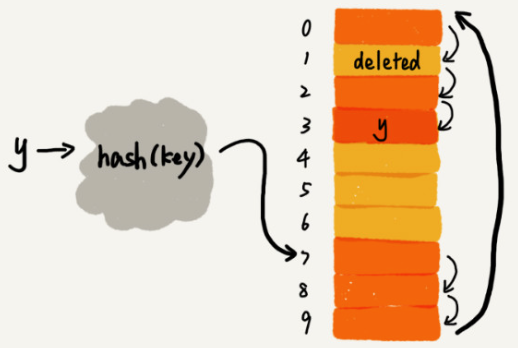 search for
search for y in hash table when there is a deleted element(Linear Probing)
- No matter which probing method is used, when there are not many free slots in the hash table, the probability of a hash conflict is greatly increased. In order to ensure the operation efficiency of hash table as much as possible, in general, we will try to ensure that there is a certain percentage of free slots in the hash table.
- We use load factor to indicate the number of free slots.
load factor = number of elements / length of the hash table
Advantages of Open Addressing
- Better Cache Performance: This method often benefits from better cache performance due to data contiguity.
- Space Efficiency: Open addressing does not require additional structures as all data is stored within the initial array.
Disadvantages of Open Addressing
- Clustering: Certain probing techniques, especially linear probing, can lead to clustering where many consecutive elements become filled, slowing down the insertion and search processes.
- Load Factor Limitations: Using this method leads to a more costly conflict. To ensure efficient operation, open addressing schemes require careful management of the load factor, usually keeping it below 0.7 or 0.8.
Chaining
Chaining is a straightforward and widely used method to handle collisions. In this approach, each slot contains a linked list (or another dynamic data structure like a tree) to store all the key-value pairs that hash to the same index.

Advantages of Chaining
- Simplicity: Chaining is simple to implement and understand.
- Stable Performance: The performance degrades gracefully; even in the worst case, the data structure degrades to a linked list or tree search.
- Less Sensitive to Hash Functions: Chaining is more forgiving with non-ideal hash functions since the performance doesn’t degrade drastically if many keys hash to the same index.
Disadvantages of Chaining
- Memory Overhead: Each entry requires additional memory for pointers in the linked lists or trees.
- Cache Performance: Chaining can lead to poor cache performance due to non-contiguous memory storage of the entries.
- Not Suitable for Serialisation: The Chaining method contains pointers, which are not as easy to serialise.
Reference:
- Wang, Zheng (2019) The Beauty of Data Structures and Algorithms. Geek Time.
