
Query processing is a fundamental aspect of database management systems (DBMS), which takes a user query — usually written in a high-level language like SQL — and transforms it into an efficient execution plan. This process is crucial, as the efficiency of query processing directly impacts the performance and response time of a DBMS.
The primary goal of this process is to translate queries into the most efficient form possible, optimizing resource use and ensuring quick retrieval times.
- The Query Processing Pipeline
- The Core of Query Processing: Query Optimisation
- Query Processing in Distributed Databases
The Query Processing Pipeline
The journey from query to result set follows a multi-stage pipeline, each with its critical functions:
-
Parsing and Translation: When a query arrives, the DBMS first checks the syntax and semantics of the query to ensure it’s valid. It then translates the high-level SQL query into an equivalent low-level relational algebra expression.
-
Optimization: The optimizer is where much of the “magic” happens. This component assesses multiple possible strategies or execution plans for the query, often using heuristics, cost-based analysis, or a combination of both to select the most efficient plan.
-
Execution: The chosen execution plan is then carried out by the database’s engine. This involves accessing the data storage to fetch or manipulate the actual data according to the plan’s operations.
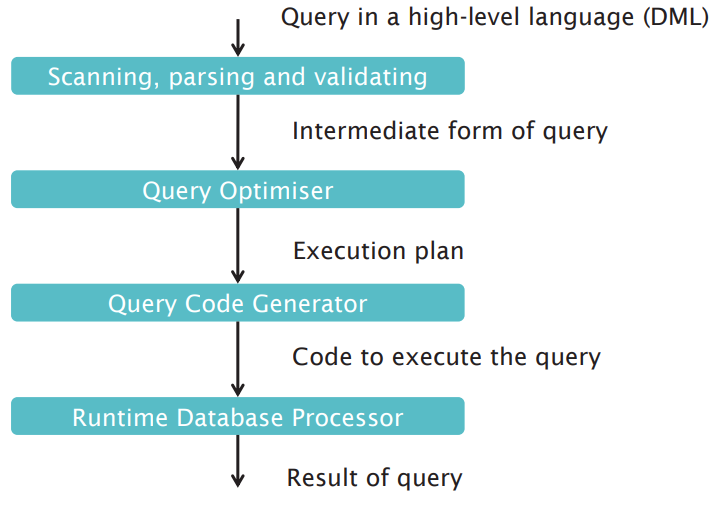 Query Processing
Query Processing
Query Plans in Query Processing
In general, query plans contain Logical Query Plan and Physical Query Plan.
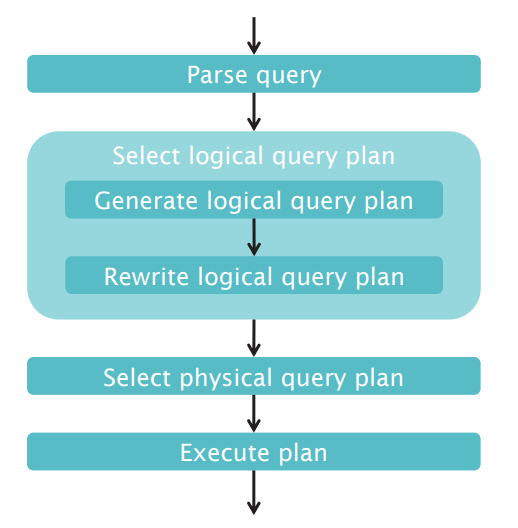 Query Processing
Query Processing
- Logical Query Plan
- algebraic representation of query
- operators taken from relational algebra
- abstract!
- contains:
- Cost estimation
- Improving logical query plans
- Cost-based plan selection
- Join ordering
- Physical Query Plan
- algorithms selected for each operator in plan
- execution order specified for operators
- contains:
- Physical query plan operators
- One-pass algorithms
- Nested-loop joins
- Two-pass algorithms
- Index-based algorithms
The Core of Query Processing: Query Optimisation
- A challenge and an opportunity for relational systems
- Optimisation must be carried out to achieve performance
- Because queries are expressed at such a high semantic level, it is possible for the DBMS to work out the best way to do things
- Need to start optimisation from a canonical form
Why is Query Optimization Critical?
The optimization stage is particularly crucial because:
-
Resource Utilization: An optimized query minimizes the use of CPU, memory, and disk I/O, which are precious resources, especially in large-scale operations.
-
Response Time: For user-facing applications, the response time can be critical. Efficient queries mean faster responses.
-
Concurrent Workload Management: Databases often handle multiple queries simultaneously. Optimization ensures that the workload is managed efficiently without taxing the system unnecessarily.
Query Optimization Techniques
Query optimizers utilize several techniques to streamline query processing:
-
Cost-Based Optimization: This technique uses statistics about the data, like indices and data distribution, to estimate the cost (in terms of resource usage) of various query plans, selecting the one with the least cost.
-
Rule-Based Optimization: Applies a set of predefined rules and heuristics to choose an execution plan, such as pushing selections and projections as close to the leaves of the query tree as possible.
-
Query Rewrite: Some queries can be rewritten for better performance. For example, a subquery might be transformed into a join.
Challenges in Query Optimization
Despite advanced optimization techniques, query processing can face challenges like:
-
Data Skew: Uneven distribution of data can lead to inaccurate cost estimations, causing the optimizer to select a non-optimal plan.
-
Complex Queries: Queries with multiple joins, subqueries, or complex conditions can be challenging to optimize efficiently.
-
Dynamic Data: As the underlying data changes, previously optimal plans may become inefficient, necessitating re-optimization.
Query Processing in Distributed Databases
In distributed databases, query processing becomes even more complex due to factors like network latency, data replication, and the need for data localization. Optimizers must consider the cost of data movement across the network and the efficiency of distributed transactions.
